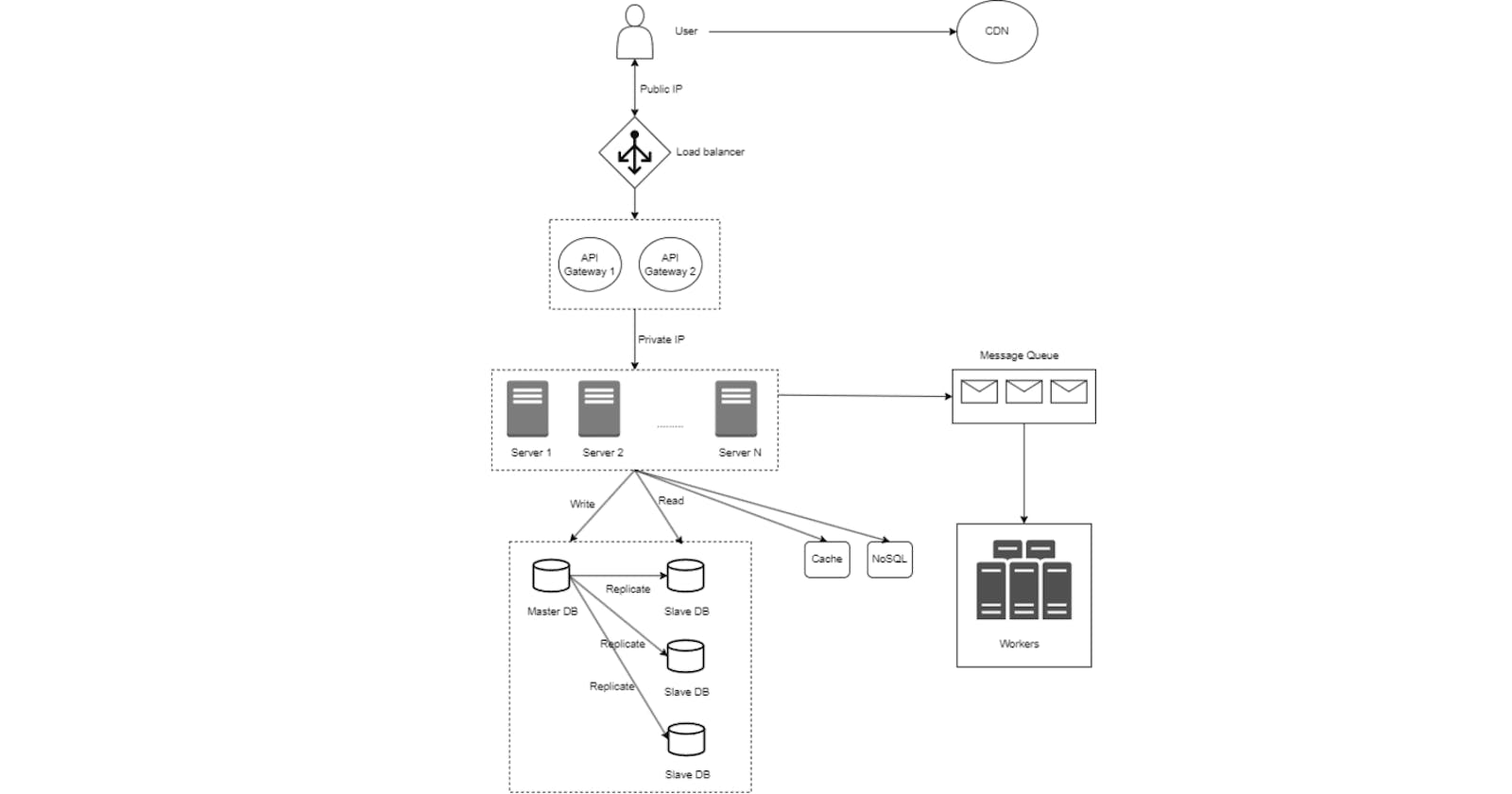


Design a microservice system is always challenging. The process of designing a microservice is like a journey. In this article I'm going to cover a high level overview of a ideal system.
I've inspired to write this article from the book System Design Interview written by Alex Xu. He is a co-founder of the site ByteByteGo. As a learner I found those recourses are very useful. You can also check out those.
Step-1: single server
Let's start everything from zero. We have few users for our application. So, start with a single monolithic server. The server will contain all the components like application, database, cache etc.

The flow is pretty simple. Users send request to the web server. The web server then send responses to the users with the help of application. The application uses the database or cache for the appropriate data.
Step-2: separate the application and the database
If the user and traffic grows enough, single server is not enough. The next step can be separate the data and the application layer. So, one server for our application which will handle the web/mobile traffic and the another one is for our database. Now we can scale them independently.

Here, I'm considering the relational database. Because it fits with almost all kind of enterprise applications. Also, non-relational databases are easy to scale. On the other hand there are many factors to scale relational databases. Thing should be considered for non-relational databases are the following.
Application needs low latency.
Unstructured data.
Need to store massive amount of data.
Step-3: Horizontal scaling instead vertical scale
This part covers the web tier scaling. Vertical scaling or scale up means adding more resources like CPU, RAM etc. to our existing server which is bad for several reasons.
Single point for failure. If the server goes down for a reason, the entire application is down.
Limited resources. We can't add unlimited resources to a servers.
Assume a scenario, an application needs more resources in some months in a year. Other times we don't need extra resources. In that case, our application will wasting memory in the idle months.
Another approach is the Horizontal scaling or scale-out means adding more server. So, instead of one single server, we will add more servers to counter the increasing traffic.
But now there is a problem here. When a user sends a request to our application, which server will receive the request. The solution is the load balancer.
Adding Load balancers
Using a load balancer, when a user sends a request to our application using the URL, first the load balancer takes the request and then forward it to the appropriate server. Load balancers do the following
The servers are connected by the internal private IP addresses. So, they are unreachable directly by the users. On the other hand Load balancers are connected by the public IP. So, the users can connected directly to the load balancers. From security perspective this is a good idea.
Evenly distribute the traffic among the servers. So, no server sits idle while other one is serving heavy traffic.
Load balancers tracks the health and Ip addresses of the servers. If any server crashed or gets offline or overloaded, we can add new healthy servers. The load balancers can easily track those servers. Based on algorithms, it distributes the traffic.

But sometimes, the load balancer is not enough. We need another tool which is the API Gateway. We can sit this between the load balancer and the servers.
API Gateways
There can be some common jobs which may need to implement and run on each servers which can be decouple, separate and unified from the servers. That's why API Gateway comes into a picture. API Gateways do the following
Authentication and authorization
Rate limiting
Decouple services
Caching
Reverse proxy
Monitoring, Logging etc.

From now, the web tier looks good. Now go to the data tier.
Step-4: Scale data tier
While the web tier is stateless, the data tier if stateful. We persists data into this tier which is not easy to scale. I've added some common techniques.
Database replication
This technique is also known as master-slave replication. There is only one master database which is the original one. This master copy is used for only write(insert, delete, update) operations. We have clone/copy slave databases from the master one. The slave databases are meant for read operations only.
But if our frequent operations are write, then this technique may not suitable. But this will be the best fit for most applications where read operations are frequent. Slave databases gets latest updates from the master in timely manner.
If the master database goes offline, one of the replica will be the master. In production system there are some complicated steps need to get the up-to-date data. I skip those here.
If only one slave database is present and it goes offline then the master temporarily serves the read operations.
Clearly we can see database replication has many advantages like better performance, reliability and high availability. There is less chance to loose data and we can run more queries parallelly.

Database scaling
Like web application scaling, the database has 2 types of scaling and they are vertical and horizontal. Like web application scaling, vertical scaling is meant for adding more resources like CPU, RAM etc. Same problem like the web tier.
Horizontal scaling: sharding
As, database has states, we can't scale or add servers like we can do in the web tier. The horizontal scaling in database is called sharding. Sharding makes a large database into smaller and easily manageable parts. Each part is called shards. Each shard shares the same schema. The common sharding strategies are
Key based
Range based
Directory based etc.
There are some drawbacks of using sharding like resharding, celebrity problem, join and de-normalization. Also there are some performance problems. So, we should properly design our system while choosing shard.
Step-5: Cache
When millions of users uses an application, imagine millions of read operation occurs in our databases. Even if we are using master-slave model, querying from a database is costly and slow. When frequent of same responses needed, it is not worthy to get the result from the database. Hence Cache is a good choice. Cache is a temporary storage area that stores the result of expensive responses and frequently accessed data. So, the responses for those data is more quick. As it is a temporary storage, it is much faster than the databases. The workflow is the following
If data exists in cache, read data from cache.
If data doesn't exist in cache, save data to cache.
So, the web tier first looks data in the cache-tier not the data-tier. Also, we should careful for using cache for the following cases.
Keep consistency. If the data is likely changing constantly, we shouldn't cache those. Also we should sync data and cache in timely manner.
Set expiration. Otherwise the data will be stored permanently. Those data will be redundant after a certain period. Also, don't expire data frequently.
Eviction policy. Cache can be full. In that case we may need to remove existing items. This is called the cache eviction. Popular eviction policies are LRU(Least recently used), FIFO(First in First out).

Step-6: Message Queue
Message Queues are used for asynchronous communication. So, no service will wait for another service's response. Many proven microservice design patterns need asynchronous communication. Also there are several use cases like batch processing, rate limiting, decoupling between services, message ordering etc. In real world, message queue plays a vital role in microservice architecture.
There are 2 parties in a message queue architecture. One is the Publishers/Producers who create message and the other is the Consumers/Subscribers. The area of message queue is huge. I'm going deep into that.

Assume, our requirement is batch processing. Now integrate message queue in our architecture.

Step-7: Shared data storage
If we have to store some states then it is challenging in microservice pattern. For example, authorizing a user. Imagine, a user logged into server A. Server A stores the session information of the user. Now, if a request from the user routed to Server B, Server B will again ask user to log in. So, we need a shared storage where we can store this information and easily scale.
Since cache is temporary and relational databases are slow, costly and hard to scale, non-relational database can be a choice here. NoSQL databases are easy to scale.

Step-8: Content delivery network(CDN)
CDN servers cache static contents like images, videos, CSS, JavaScript files etc. CDN is a network which is geographically distributed.
When a user requests for a static content, a CDN server first find a nearest server from the user. Then serve the requested file. This is very helpful when users watch movies(YouTube, Netflix) or visit a website which uses images(Amazon, Pinterest). This concept quickly serve static contents to the users. The flow of the CDN is
First a user requests a static content to the CDN.
If the content is available in the nearest CDN server's cache, send it to the user.
If not available then the CDN server requests it to the origin. It can be our web servers or cloud storage like Amazon S3.
The origin returns the content including an optional HTTP header Time-to-Live(TTL). The content will be removed after the TTL.
The CDN then returns the content to the user.
Again another user requests for the same content, the CDN will return until TTL has not expired.
We can see the CDN is great for many use cases. But there are some considerations as follows.
CDNs are too much costly. So, we should keep necessary static contents in CDN.
Set appropriate expiration(TTL) for the contents. Not too long or not too short.

Step-9: Logging, metrics, automation
In a big microservice environment those things are crucial.
Monitor error logs. This helps which parts are failed and what are the problems.
Check health status of each components.
Host level: CPU, Memory, disk etc. usage.
Aggregate level: performance of web tier or data tier or cache tier etc.
Business level: daily active users, retention, revenue etc.
Automate things for productivity. For example, CI/CD.
Step-10: Data centers
If the users are geographically distributed then data centers are useful. Most of the cloud services distributed their servers geographically. Using data centers, we can serve users by their closet servers. This will help good user experience and we can distribute the incoming traffic. Also, there are technical challenges using data centers.
Summary
I've come to the end. There are lots of things in the microservice era. But I tried to focus on the necessary and general things. I hope I didn't miss any of the necessary things. If I missed anything please let me know in the comment section. Let's summarize this whole article
Scale web-tier horizontally.
Use load balancer for distributing web-tier load.
Scale database using sharding.
Use database replication.
Cache data as you can.
Use Message Queue for asynchronous communication.
Use CDN for static contents.
Monitor entire system.
Collect logs.
Use automation tools.
Use data centers
If you are till this end then thanks for the reading. I hope you enjoyed this article. Don't forget to like and share if this article is helpful to you.